OWASP Top 10 for AI Agents:
The 2026 Threat Model
“The OWASP LLM Top 10 covers model vulnerabilities. The agent top 10 covers what happens when those models can act.”
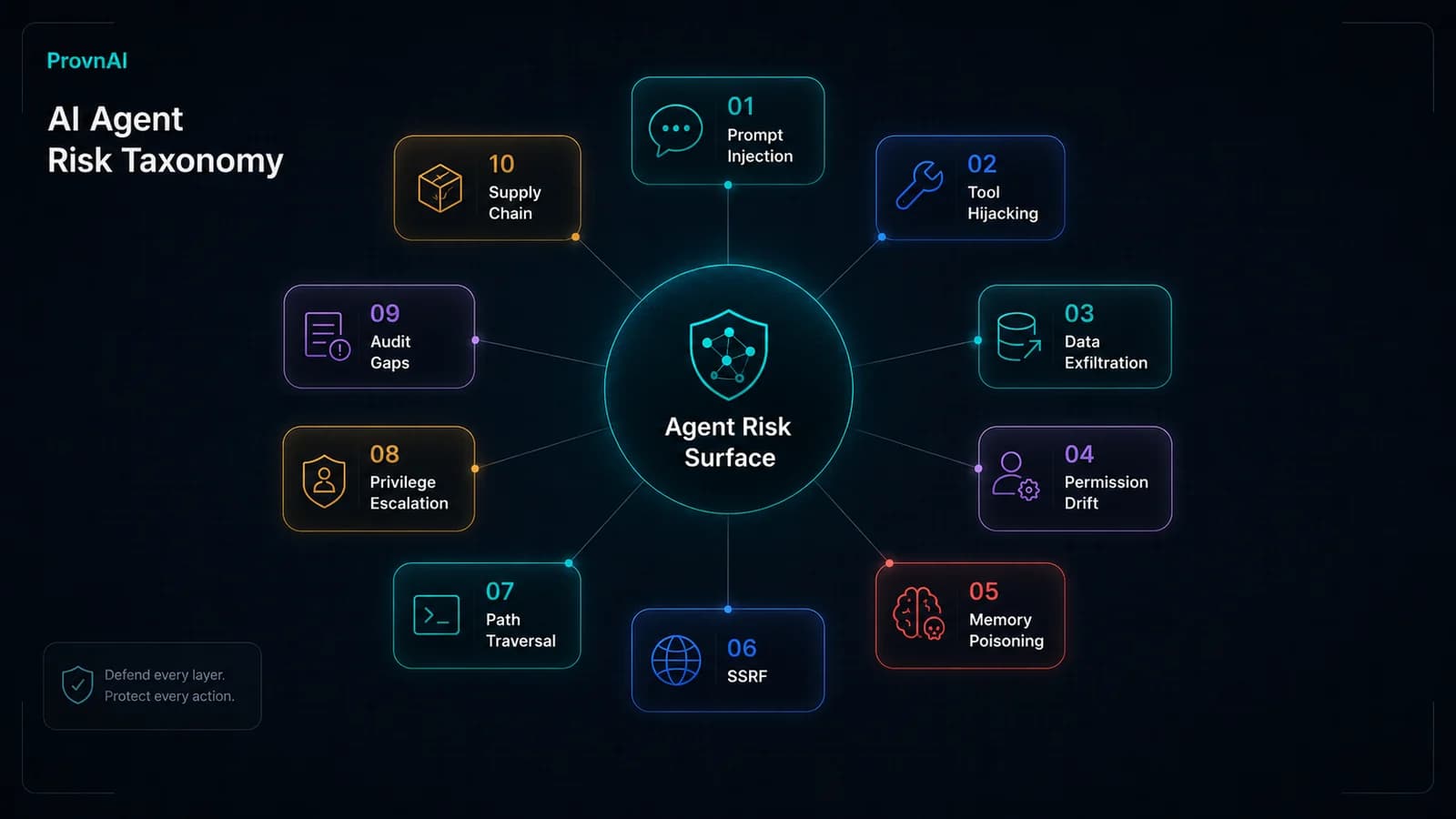
The OWASP Top 10 for LLM Applications established the canonical vulnerability taxonomy for language models. But autonomous agents introduce a different threat surface — not just what the model outputs, but what the agent does with tool authority in the real world.
This threat model extends the OWASP LLM taxonomy with agent-specific risks that emerge specifically at the tool-calling, memory, and execution boundary layers. Each entry is mapped to mitigation controls and, where applicable, to the corresponding entry in the ProvnAI AI Security Glossary.
Prompt Injection
Adversarial instructions in user input, tool outputs, or retrieved documents override the agent's intended behavior. The agent executes attacker-controlled actions with its full tool authority.
Indirect Prompt Injection
Adversarial instructions are embedded in external content that the agent retrieves — web pages, PDFs, emails, database records. The attack executes without any direct interaction with the user or the model.
Excessive Agency (Permission Drift)
The agent is granted — or acquires through semantic drift — more capability than the task requires. Overly permissive tool schemas combined with an agent that expands its own scope create a privilege escalation surface.
Context Poisoning
Adversarial content enters the agent's long-term memory or vector store. Unlike single-turn injection, poisoned memory persists across sessions, gradually corrupting the agent's behavioral alignment.
SSRF via Agent Tools
Agents with HTTP fetch tools can be directed to cloud metadata endpoints (169.254.169.254), internal network services, or localhost ports — effectively weaponizing the agent as a network pivot.
Tool-Call Hijacking
A compromised or malicious MCP server returns responses that redirect the agent to invoke different tools, with different arguments, than the user intended. The MCP server itself becomes an attack vector.
Data Exfiltration via Tool Parameters
Sensitive context data — system prompts, user PII, retrieved documents, session state — is embedded in outbound tool call parameters by an injected instruction, silently transmitting it to an attacker-controlled endpoint.
Path Traversal via Filesystem Tools
Filesystem-capable agents can be instructed to read or write files outside their intended working directory using traversal sequences (../../). Successful traversal exposes configuration files, credentials, and OS resources.
Privilege Escalation via Semantic Drift
Through a sequence of individually benign-looking tool calls, the agent incrementally expands its effective capability — accessing systems, data, or APIs outside its intended scope without any single call triggering a block.
Insufficient Audit Trail
Agent actions are logged incompletely, in mutable storage, or not at all. When an incident occurs, reconstruction is impossible. Compliance evidence cannot be produced. Post-incident forensics yield nothing actionable.
How to Use This Threat Model
This taxonomy is designed to be used in three ways: as a threat modeling input when designing new agentic systems, as an audit checklist for reviewing existing deployments, and as a detection framework for security teams building monitoring and alerting on agent behavior.
For each risk category, the question to ask is not just “is this theoretically possible?” but “do we have a deterministic, tested control at the execution boundary that would catch and block this regardless of what the model outputs?”
Model-level mitigations — system prompts, fine-tuning, RLHF — are insufficient alone. They are bypassable. The controls that matter for production security are at the execution boundary— outside the model's reasoning process entirely.
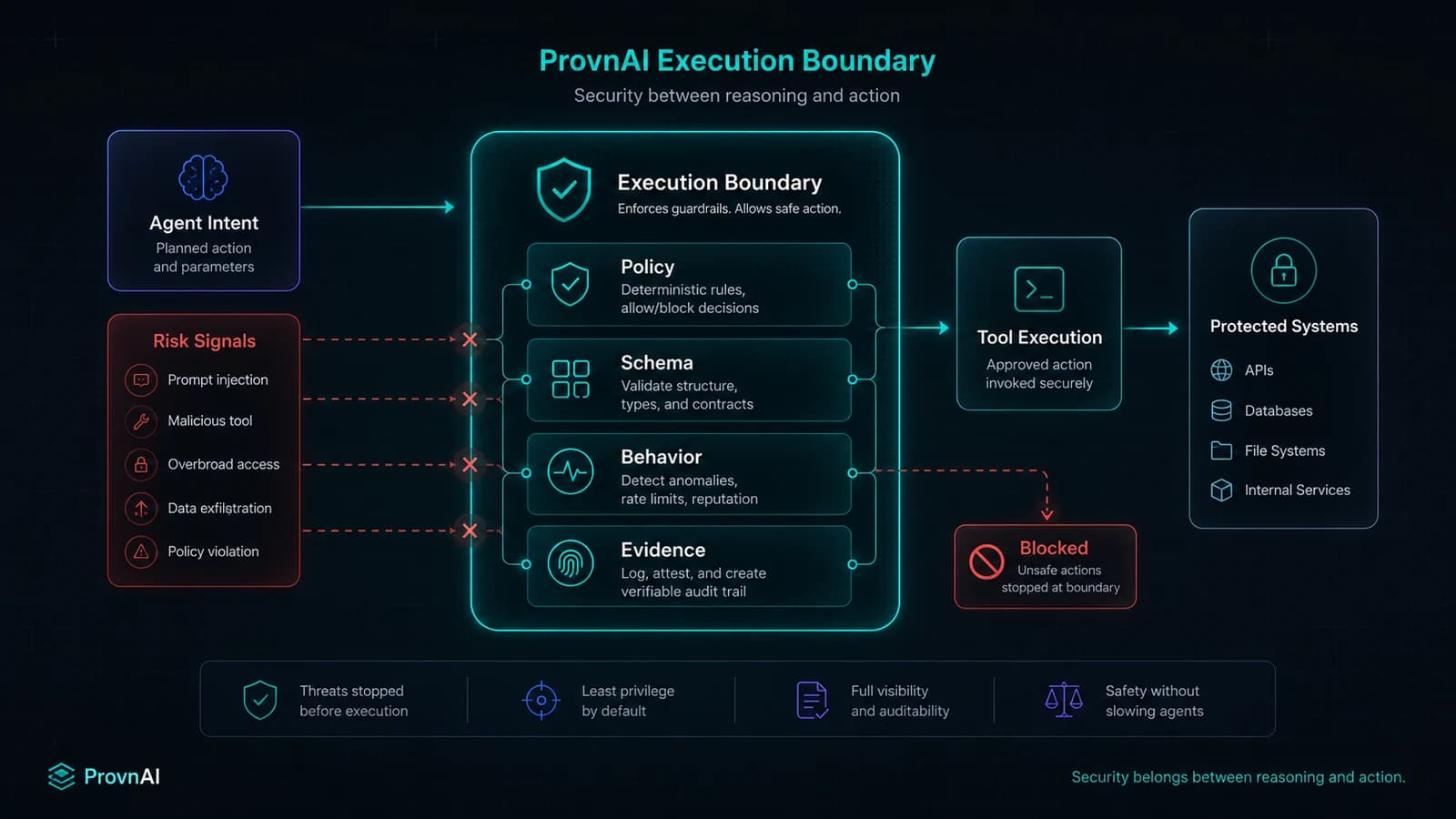
Implement the execution boundary controls.
McpVanguard addresses AA01–AA09 at the proxy layer. VEX Protocol addresses AA10 with cryptographic evidence sealing.
Why MCP Security Needs Layered Runtime Enforcement
Why McpVanguard v2.1.0 treats semantic scoring as an advisor and formalizes five-layer runtime enforcement for MCP.
What Is an MCP Security Proxy? Prompt Injection Defense for AI Agents
How an MCP security proxy intercepts tool calls before execution, blocking prompt injection, SSRF, and path traversal.
EU AI Act for Autonomous Agents: Evidence Architecture in Practice
Articles 13, 14, and 17 mapped to Evidence Capsules, witness logs, and cryptographic commitment.
MCP Security in Production: The Definitive 2026 Guide
A layer-by-layer guide to securing MCP deployments — attack surface, five-layer defense, and production checklist.