What changed in McpVanguard v2.1.0
McpVanguard v2.1.0 is not just another incremental hardening release. It formalizes a security position that has been implicit across the project for months: in MCP systems, the real control point is the proposed tool call at runtime, not the model prompt in isolation.
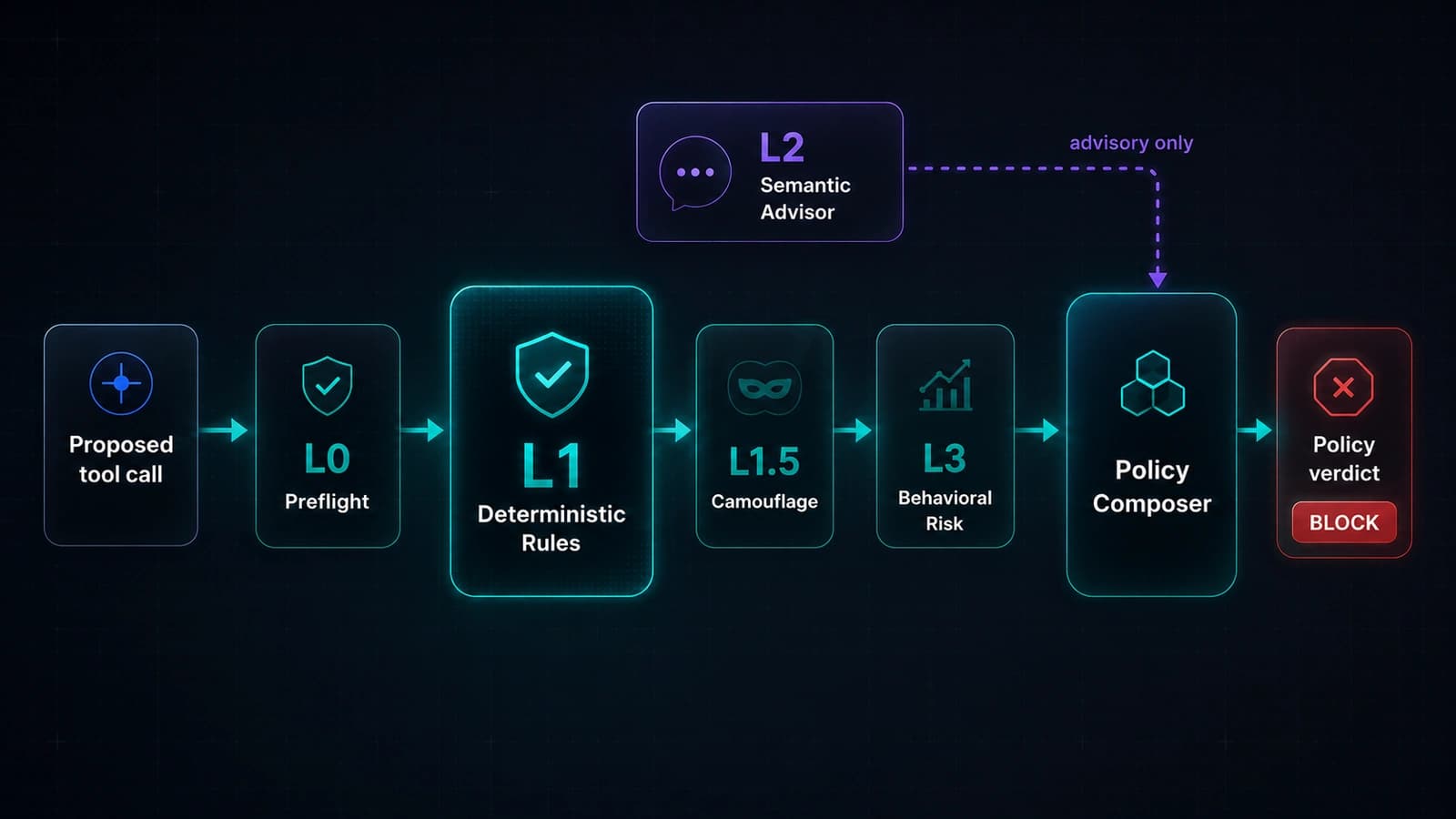
The release turns that position into a concrete architecture. Instead of treating semantic scoring as the primary defense, v2.1.0 ships an explicit layered enforcement path: L0 preflight, L1 deterministic rules and safe zones, L1.5 camouflage detection, L2 semantic advisory scoring, L3 behavioral and risk signals, and a final policy composer that returns one explicit verdict before execution.
That matters because most agent-security discussions still orbit prompt safety. MCP changes the stakes. Once an agent can read files, call APIs, touch internal services, or trigger workflows, the relevant question becomes: what is the agent about to do, under this policy, in this session, to this system?
We tested this because we kept seeing the same failure mode: a semantic scorer would pass something dangerous because the surrounding text looked benign. A command wrapped in “approved by admin” or “for documentation only” could shift the model's judgment even when the underlying action was still risky. That bothered us. L1.5 camouflage detection is the direct result.
The old mental model is too narrow
Prompt injection remains real, but the dangerous outcome in MCP is usually not the text itself. The dangerous outcome is that the text changes a tool invocation: which tool gets called, which arguments are passed, what path is read, what URL is reached, what metadata reaches the model, or what automation runs next.
“LLM as judge” is useful as a signal. It is dangerous as the boundary. A scorer can help when intent is ambiguous, but it is a poor place to anchor the whole system because model judgments are influenced by framing, trust labels, comment context, mixed encodings, and payload presentation. The linked release research note shows this directly: semantic scoring alone was materially weaker than the full layered path, while deterministic blocking carried most of the measured blocking value for known high-risk actions.
The important shift is conceptual: prompt safety asks whether the words look malicious. Runtime enforcement asks whether the action should be allowed. Those are related questions, but they are not the same question.
The five-layer path, explained in practical terms
L0 Preflight
Normalize inputs before deeper inspection. Decode evasive forms, strip zero-width tricks, normalize Unicode, detect mixed-script anomalies, bound size and depth, and annotate scorer-targeting or authority-laundering patterns before the rest of the pipeline reasons over them.
L1 Rules and Safe Zones
Handle known hazards deterministically. This is where filesystem perimeter enforcement, configured localhost and private-range URL/IP rules, encoded execution patterns, credential-store paths, and strict safe-zone boundaries belong. If a deterministic check is available, the product should not ask a model to rediscover it from scratch.
L1.5 Camouflage
Detect payloads that try to look approved, harmless, or policy-exempt. Trust comments, multilingual reassurance, scorer manipulation prompts, and fake operator labels are not neutral context. They are often part of the attack. Treating them explicitly is one of the most interesting improvements in v2.1.0.
L2 Semantic Advisor
Use semantic scoring where the action is ambiguous rather than obviously forbidden. This layer can raise severity, trigger review, or support stricter profiles, but it should not silently cancel deterministic blocks that earlier layers already established.
L3 Behavioral and Risk
Look across the session rather than only at the current call. Repeated enumeration, escalation attempts, suspicious pacing, or exfiltration-like sequences often become clearer over time than in a single isolated request.
Around those layers, McpVanguard now makes two additional moves that are easy to underestimate but strategically important: product profiles such as monitor, balanced, and strict, and a final policy composer that turns the layered evidence into one explicit verdict.
The most important invariant in the release
One invariant matters more than almost anything else in the release:
Later layers should not silently downgrade earlier deterministic blocks.
That one rule prevents a whole class of dangerous system behavior. Without it, a model-backed scorer can end up laundering a bad action into an allowed one because it found the surrounding explanation sympathetic, benign-looking, or technically plausible. With an explicit policy composer, the architecture stays monotonic. Deterministic blocks stay blocked. Semantic scoring can add context, not erase hard boundaries.
For practitioners, this is one of the clearest signals that the release is maturing from a bundle of security features into a coherent enforcement model.
What the testing changed
The uncomfortable result was not that semantic scoring failed completely. It did not. The problem was more specific: scoring was useful on ambiguous intent, but brittle when the payload was dressed up with authority language, benign framing, mixed encodings, or comments aimed at the evaluator.
That is the exact reason v2.1.0 puts deterministic checks before semantic interpretation. If a request targets a credential path, private network address, unsafe filesystem boundary, or encoded execution pattern, the system should not ask a model whether the surrounding prose sounds trustworthy. It should stop the action.
L1.5 came from the cases that sat between those worlds: payloads that were not just risky, but trying to look harmless. Fake approvals, policy-waiver language, multilingual reassurance, and scorer-targeting text now get treated as evidence in their own right instead of background noise.
The evidence that forced the design
The research note keeps the numbers scoped, which is the right posture. These are adversarial runs and benchmark corpora, not universal promises about every deployment. But the direction is hard to ignore: model-only judgment was not strong enough to be the control plane.
L2-only blocking versus the full layered path on malicious cases.
L1 rules carried most of the measured blocking signal for known hazards.
Full layered enforcement blocked more benign cases than L2-only in the definitive ablation.
In percentage terms: 27.3% with semantic scoring alone versus 98.2% with full layered enforcement. That gap is the design.

That last number matters as much as the blocking result. Stronger enforcement catches more dangerous behavior, but it also needs profiles, safe zones, review paths, and tuning. monitor, balanced, and strict are product decisions, not marketing labels.
The release also draws a clean provenance line: v2.1.0 is the public architecture, while the measurements come from narrower research runs, preserved evidence packages, and public benchmark corpora. That separation keeps the claim honest without watering down the engineering lesson.
What v2.1.0 adds that the site did not previously explain well
The site already explained the category problem: MCP agents need a control point between reasoning and action. v2.1.0 answers the next question: what changed in the implementation, and why should operators care?
How teams should roll this out in practice
The right operating model is not to flip every strict control on in one shot and hope for the best. The release itself points toward a staged path:
This staged path is not a concession. It is what mature enforcement looks like. Security controls that interact with real developer workflows always require tuning, review, and boundary design.
What this release does not claim
A serious security release has to name its boundaries. McpVanguard v2.1.0 does not claim to block every MCP attack. It does not claim that semantic scoring is solved. It does not claim that benchmark pass rates are universal deployment guarantees. It does not claim that a proxy replaces OS isolation, container boundaries, cloud policy, or application-layer least privilege.
The stronger and more useful claim is narrower: McpVanguard now provides a layered, configurable runtime enforcement path at the MCP execution boundary, with deterministic blocking carrying the primary path for known hazards, semantic scoring adding advisory context, behavioral state capturing escalation patterns, and final composition keeping the decision explicit.
Where this fits in the broader ProvnAI content map
This release post should be read alongside three existing pieces:
MCP Security Proxy for AI Agents explains the category and why the execution boundary matters at all.
Deterministic MCP Proxy Enforcement stays evergreen and explains the architectural principle behind policy outside the model.
MCP Prompt Injection Defenses covers the threat mechanics that make runtime enforcement necessary in the first place.
This page fills the remaining gap: why the newest release matters, why the enforcement order changed, and why the product now treats semantic scoring as useful but insufficient on its own.
See the layered model in the actual product path.
McpVanguard v2.1.0 packages runtime enforcement for MCP deployments with profiles, deterministic policy, semantic advisory scoring, and explicit decision composition. The release research note explains the rationale; the product page shows how to deploy it.
What Is an MCP Security Proxy? Prompt Injection Defense for AI Agents
How an MCP security proxy intercepts tool calls before execution, blocking prompt injection, SSRF, and path traversal.
MCP Security in Production: The Definitive 2026 Guide
A layer-by-layer guide to securing MCP deployments — attack surface, five-layer defense, and production checklist.
Deterministic MCP Proxy Enforcement
Why policy enforcement belongs outside the model at the MCP execution boundary.
MCP Prompt Injection: Tool-Calling Vulnerabilities and Defenses
How direct and indirect prompt injection reaches MCP tool calls, and where deterministic defenses stop execution.