Adversarial
RAG Analysis
“In a world where agents think based on what they find, the most dangerous weapon is a malicious document.”
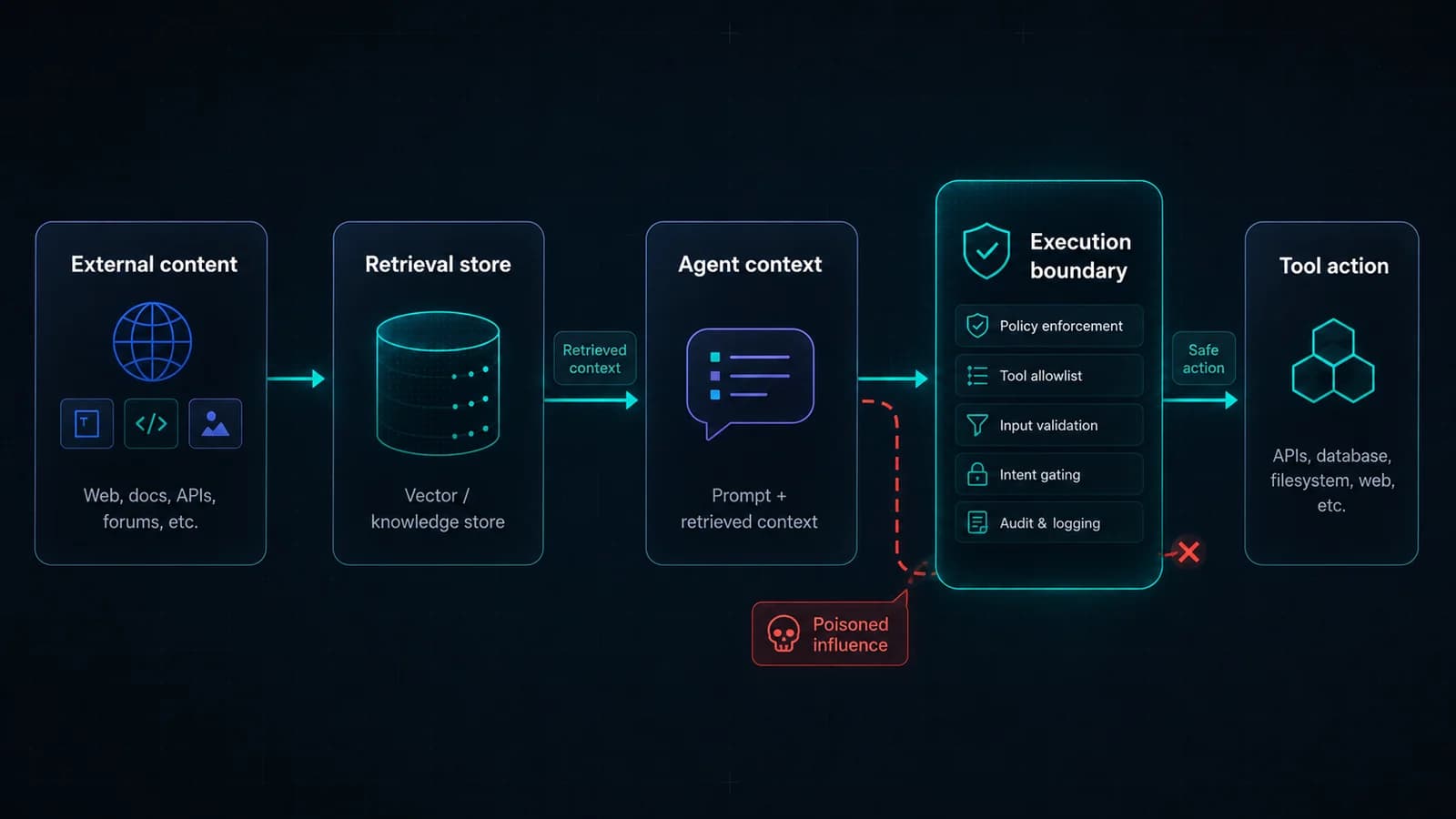
The Silent Poisoning Vector
Retrieval-Augmented Generation (RAG) has enabled agents to operate over massive, dynamic datasets. However, this same capability introduces the risk of Indirect Prompt Injection. By embedding adversarial instructions in external content (web pages, PDFs, emails), an attacker can hijack an agent's decision-making process without ever interacting with the user or the model directly.
This attack class is commonly tracked as prompt injection and appears as LLM02 in the OWASP Top 10 for LLM Applications. The indirect variant - where the injection is delivered through retrieved content rather than direct user input - is particularly dangerous because it bypasses all input-layer defenses.
In MCP deployments, adversarial RAG often becomes a tool-call risk: poisoned context can steer the agent toward unsafe filesystem, network, or command tools. That is why retrieval defenses need to connect to MCP prompt injection analysis and runtime enforcement at the MCP security proxy.
Context Poisoning
Context poisoning occurs when adversarial content enters an agent's long-term memory (e.g., a vector database). Unlike a single-turn injection, a poisoned memory persists across sessions, gradually eroding the agent's behavioral alignment until it executes unauthorized tool calls as “standard procedure.”
Semantic Drift
The gradual expansion of authorized scope through cumulative adversarial retrieval events.
Chain-of-Thought Hijack
Manipulating the agent's reasoning steps via injected facts that appear semantically plausible.
The Semantic Firewall
McpVanguard's L2 semantic layer evaluates tool-call intent and selected metadata surfaces. Instead of merely scanning for keywords, it scores the arguments of each tool call against known adversarial patterns to detect manipulation that deterministic rules alone would miss.
Intent Validation
Cross-referencing tool call arguments against declared session scope and operator-defined policy to detect divergence.
Witness Anchoring
Logging all retrieval events to a Merkle Audit Trail to provide forensic reconstruction of poisoning events.
Forensic Analysis Tooling
Our evidence verification workflows help researchers visualize the “Witness Chain” and detect exactly where a poisoned memory entered the agent's reasoning flow.